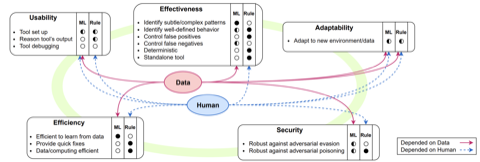
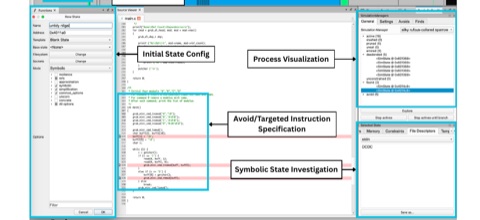
AI-Enabled Abuse
How people abuse AI systems, and how people perceive and respond to abusive AI-generated media.
AI Sexual Content • Norms, Rules, & Moderation of AI Sexual Community • Longitudinal Analysis of AI Detection Methods • Bias in AI Media Moderation • Perceptions of AI Media